
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 우아한테크코스
- 스프링트랜잭션
- 테코톡
- jsp프로젝트
- 레벨로그
- kotlin
- 백준
- 무중단배포
- ObjectCalisthenics
- 트랜잭션속성
- 리버스프록시
- subprocess에러
- DynamicWebProject
- 트랜잭션
- Google Place Photo API
- KotlinInAction
- tomcat설정
- S2139
- 코틀린뽀개기
- 객체지향생활체조
- 알고리즘
- servlet프로젝트
- mysqld.sock
- GithubOAuth
- 코틀린기초
- java
- 코틀린
- 자바비동기
- 데이터베이스락
- 트랜잭션성질
Archives
- Today
- Total
초이로그
인덱스 본문
[10분 테코톡] 라라, 제로의 데이터베이스 인덱스
[10분 테코톡] 👨🏫안돌의 INDEX
를 정리한 글
MySQL InnoDB 환경 기준
인덱스란?
사전적 정의: 색인. 쉽게 찾아볼 수 있도록 일정한 순서에 따라 놓은 목록
데이터베이스 인덱스
- 데이터베이스 테이블에 대한 검색 성능을 향상시키는 자료 구조이며, WHERE절 등을 통해 활용된다.
- SELECT * FROM member; 쿼리는 WHERE 절을 통해 검색하지 않아 인덱스가 사용되지 않는다
- 인덱스 기준 없이 데이터가 저장된 상태 ➡️ 느리다(전체 데이터에서 순차적 확인)
- 특정 기준으로 정렬된 상태 ➡️ 검색(SELECT)이 빠르다
인덱스 특징
- 인덱스는 항상 최신의 정렬상태를 유지
- 인덱스도 하나의 데이터베이스 객체
- 데이터베이스 크기의 약 10% 정도의 저장 공간 필요
인덱스 알고리즘
용어 설명
페이지: 데이터가 저장되는 단위(DB 환경에 따라 다르다. MySQL의 경우 16Kbyte)
Full Table Scan
- 순차적으로 데이터를 찾는다
- 접근 비용 감소
사용되는 경우
데이터베이스에 인덱스가 없거나 인덱스를 적용해도 성능상의 이점이 없다고 판단될 때 적용
- 적용 가능한 인덱스가 없는 경우
- 인덱스 처리 범위가 넓은 경우
- 크기가 작은 테이블에 엑세스하는 경우

(참고)
Binary Search Tree(이진 탐색 트리): 이진 탐색과 연결 리스트의 장점을 합쳐져 만들어진 자료구조
- 균형 있는 이진 탐색 트리의 시간 복잡도: O(log n)
- 균형 없는 이진 탐색 트리의 시간복잡도: O(n) ➡️ BST 장점 활용 ❌. 이를 극복하기 위한 알고리즘 중 하나가 B-Tree이다.
B-Tree(Balanced-Tree)
- 기본 데이터베이스(MySQL InnoDB 기준) 인덱스 구조
- 트리의 높이가 같음
- 자식 노드를 2개 이상 가질 수 있음

- 루트 페이지: 최상단에 위치
- 브랜치 페이지: 루트 페이지와 리프 페이지 사이에 위치. 여러 개가 존재할 수 있다.
- 리프 페이지: 최하단에 위치. 실제 데이터 페이지(클러스터링 인덱스) 또는 실제 데이터의 주소 페이지(논-클러스터링 인덱스)가 존재

인덱스의 INSERT & 페이지 분할

- OOO를 삽입하는 경우, NNN과 PPP 사이에 삽입된다.
- PPP의 이동이 있었지만 페이지 내부에서 작업되었기 때문에 큰 부담은 없다.

- ZZZ를 삽입하는 경우, 페이지가 모두 차있기 때문에 삽입할 수 없다. ➡️ 페이지 분할 발생. 데이터베이스에 부담
- 데이터베이스는 비어있는 페이지를 확보한다.
- 문제가 있는 페이지의 데이터를 공평하게 나누어 저장한다.
페이지 분할
- 페이지에 새로운 데이터를 추가할 여유공간이 없어 페이지에 변화가 발생
- DB가 느려지고 성능에 영향을 준다
인덱스의 DELETE
인덱스의 데이터를 실제로 지우지 않고 사용안함 표시를 한다
인덱스의 UPDATE
인덱스는 UPDATE 개념이 없다.
1. DELETE를 통해 기존 값(인덱스)을 '사용 안함' 표시
2. INSERT를 통해 변경된 값 삽입
UPDATE, DELETE의 경우도 WHERE 절을 사용할 때 빨라질까?
- WHERE 절로 처리할 대상을 찾기 위한 조회 성능은 향상
- 사용하지 않는 인덱스가 적용되었다면 불필요한 처리량 증가
- 사용안함 표시로 페이지 낭비 및 인덱스 조각화가 심해짐
정리
- SELECT: 성능이 향상된다
- INSERT/UPDATE/DELETE: 페이지 분할과 사용안함 표시로 인덱스의 조각화가 심해져 성능이 저하된다.
인덱스 종류
용어설명
Cluster: 1. 무리, 군집 2. 무리를 이루다
Clusterd: 군집화
Clustered Index: 군집화된 인덱스
데이터베이스에서 클러스터링의 의미
- 클러스터링
- 실제 데이터와 무리를 이룸
- 실제 데이터와 같은 무리의 인덱스
- ex) 실제 데이터가 가나다 순으로 정렬된 사전과 같은 역할
- 논-클러스터링
- 실제 데이터와 무리를 이루지 않음
- 실제 데이터와 다른 무리의 별도의 인덱스
- ex) 실제 데이터 탐색에 도움을 주는 별도의 찾아보기 페이지
CREATE TABLE member (
id int primary key,
name varchar(255),
email varchar(255) unique
);- 2개의 인덱스가 생성되는 쿼리
- primary key: 클러스터링 인덱스 자동 생성
- unique 제약 조건: 논-클러스터링 인덱스 자동 생성
클러스터링 인덱스
- 실제 데이터 자체가 정렬
- 테이블당 1개만 존재 가능
- (B-Tree의) 리프 페이지가 데이터 페이지와 동일
- 범위 검색에 유리
- 아래의 제약 조건 시 자동 생성
- primary key
- unique + not null
- 하나의 테이블에 PK와 UNIQUE+NOT NULL 제약조건의 칼럼이 함께 존재하는 경우, PK가 우선순위를 가지고 인덱스 생성
인덱스 생성 방법
1. PK를 칼럼에 적용
ALTER TABLE member
ADD CONSTRAINT pk_id PRIMARY KEY(id);2. 한 컬럼에 NOT NULL과 UNIQUE 제약 조건을 한번에 걸기
ALTER TABE member MODIFY COLUMN id int NOT NULL;
ALTER TABE member ADD CONSTRAINT nuq_id UNIQUE (id);
적용 예시

- 클러스터링 인덱스를 적용한 id 컬럼을 기준으로 데이터 정렬

- 정렬된 데이터를 기준으로 B-Tree 구조의 루트 페이지와 리프 페이지 생성
- 루트 페이지의 1000, 10001, 1002과 같은 숫자는 데이터 페이지의 주소를 의미
- 클러스터링 인덱스를 적용한 Id 칼럼을 기준으로 데이터 정렬
- 데이터가 추가되거나 삭제되더라도 정렬을 최신 상태로 유지하면서 데이터 저장

논-클러스터링 인덱스
= 보조 인덱스 = 세컨더리 인덱스
- 실제 데이터 페이지는 그대로 변경 없이 존재
- 별도의 인덱스 페이지 생성으로 추가 공간 필요(약 10%)
- INSERT 시 인덱스 생성을 위한 추가 작업 필요
- 테이블당 여러 개 존재 가능
- 리프 페이지에 실제 데이터 페이지의 주소를 담고 잇음
- unique 제약 조건 적용 시 자동 생성
- 직접 index 생성 시 논-클러스터링 인덱스 생성
인덱스 생성 방법
1. 한 컬럼에 UNIQUE 제약 조건 걸기
ALTER TABLE member
ADD CONSTRAINT unq_name UNIQUE (name);2. 중복을 허용하지 않는 UNIQUE 인덱스 생성
CREATE UNIQUE INDEX unq_idx_name
ON member (name);3. 중복을 허용하는 DEFAULT 인덱스 생성
CREATE UNIQUE INDEX idx_name
ON member (name);
적용 예시
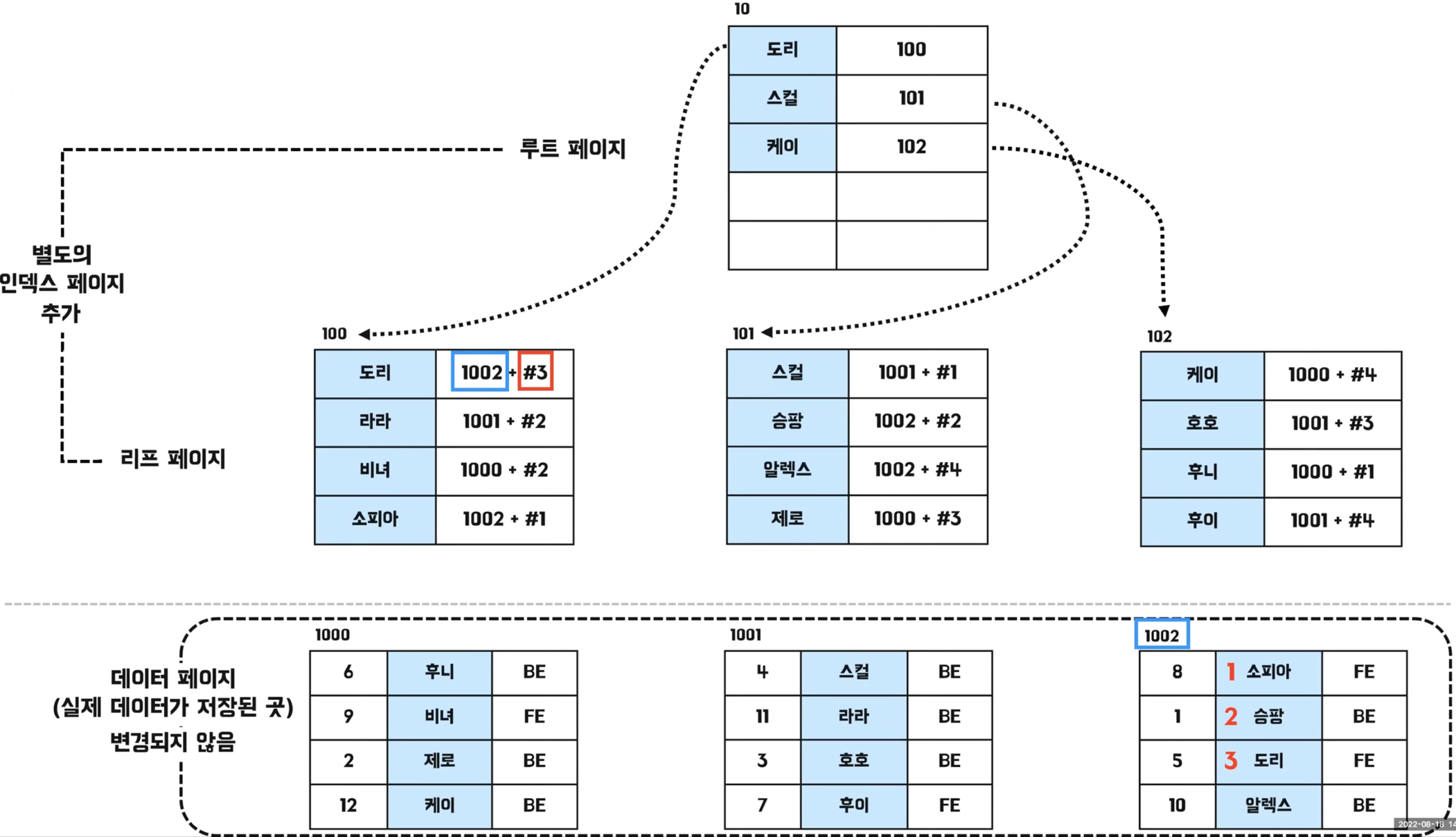
- 실제 데이터가 저장된 데이터 페이지는 아무런 변경 없음
- 클러스터링 인덱스와 다르게 별도의 name에 대한 B-Tree 구조의 인덱스 페이지 추가
- name을 기준으로 정렬되어 있음
- 리프 페이지의 "1002 + #3"에서 1002는 실제 데이터 페이지의 주소, 3은 1002 페이지의 세 번째라는 데이터 주소를 의미

클러스터링 인덱스 + 논-클러스터링 인덱스 구성

- 논-클러스터링 인덱스 리프 페이지에 데이터 페이지의 주소 값이 아닌, 클러스터링 인덱스가 적용된 컬럼의 실제 값(id 칼럼 값) 저장
- 데이터 페이지의 주소를 저장하는 경우, 데이터가 추가되거나 삭제될 때마다 인덱스 페이지의 주소값을 변경해야하기 때문에 클러스터링 인덱스 값으로 저장한다.
인덱스 적용 기준
어떤 컬럼에 인덱스를 적용해야할까?
- 카디널리티(그룹 내 요소의 개수)가 높은 것(= 중복도가 낮은 것)
- WHERE, JOIN, ORDER BY 절에 자주 사용되는 컬럼
- 인덱스는 추가 공간이 필요하다
- 조건 절이 없다면 인덱스가 사용되지 않음에 주의하자
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- 성능 저하에 영향이 있을 수 있다
- 규모가 작지 않은 테이블
- 규모가 작은 테이블의 경우 효과가 미미
인덱스 성능 비교
CREATE TABLE member (
id int primary key,
email varchar(255) unique
);인덱스 미적용 시 성능

email 컬럼 인덱스 적용 후 성능

인덱스 사용시 주의사항
- 잘 활용되지 않는 인덱스는 과감하게 제거하자
- WHERE 절에 사용되더라도 자주 사용해야 가치가 있다
- 불필요한 인덱스가 성능 저하가 발생할 수 있다
- 데이터 중복도가 높은 컬럼은 인덱스 효과가 적다
- 자주 사용되더라도 INSERT / UPDATE / DELETE가 자주 일어나는지 고려해야한다
- 일반적인 웹 서비스와 같은 온라인 트랜잭션 환경에서 쓰기와 읽기 비율은 2:8 또는 1:9이다
- 조금 느린 쓰기를 감수하고 빠른 읽기를 선택하는 것도 하나의 방법
'우아한테크코스 > 테코톡 정리' 카테고리의 다른 글
| JDK Dynamic Proxy vs CGLIB Proxy (3) | 2022.10.18 |
|---|---|
| Spring AOP (0) | 2022.10.14 |
| CI/CD와 무중단 배포 (0) | 2022.10.09 |
| 트랜잭션 (0) | 2022.10.08 |
| 스프링 트랜잭션 (0) | 2022.10.02 |
'우아한테크코스/테코톡 정리' Related Articles
more



